When to use
Always fit method = "forest" first. It is
non-parametric, makes no behavioural assumptions, and gives you the
importance hierarchy of individual attribute levels.
Fit
rf <- cj_fit(f, data = immig, method = "forest")
rf
#> Conjoint Random Forest
#> ======================
#>
#> Resolution: levels
#> Trees: 500
#> OOB Error: 40.3%
#> Observations: 2,000
#> Attributes: 9
#> Levels: 50
#>
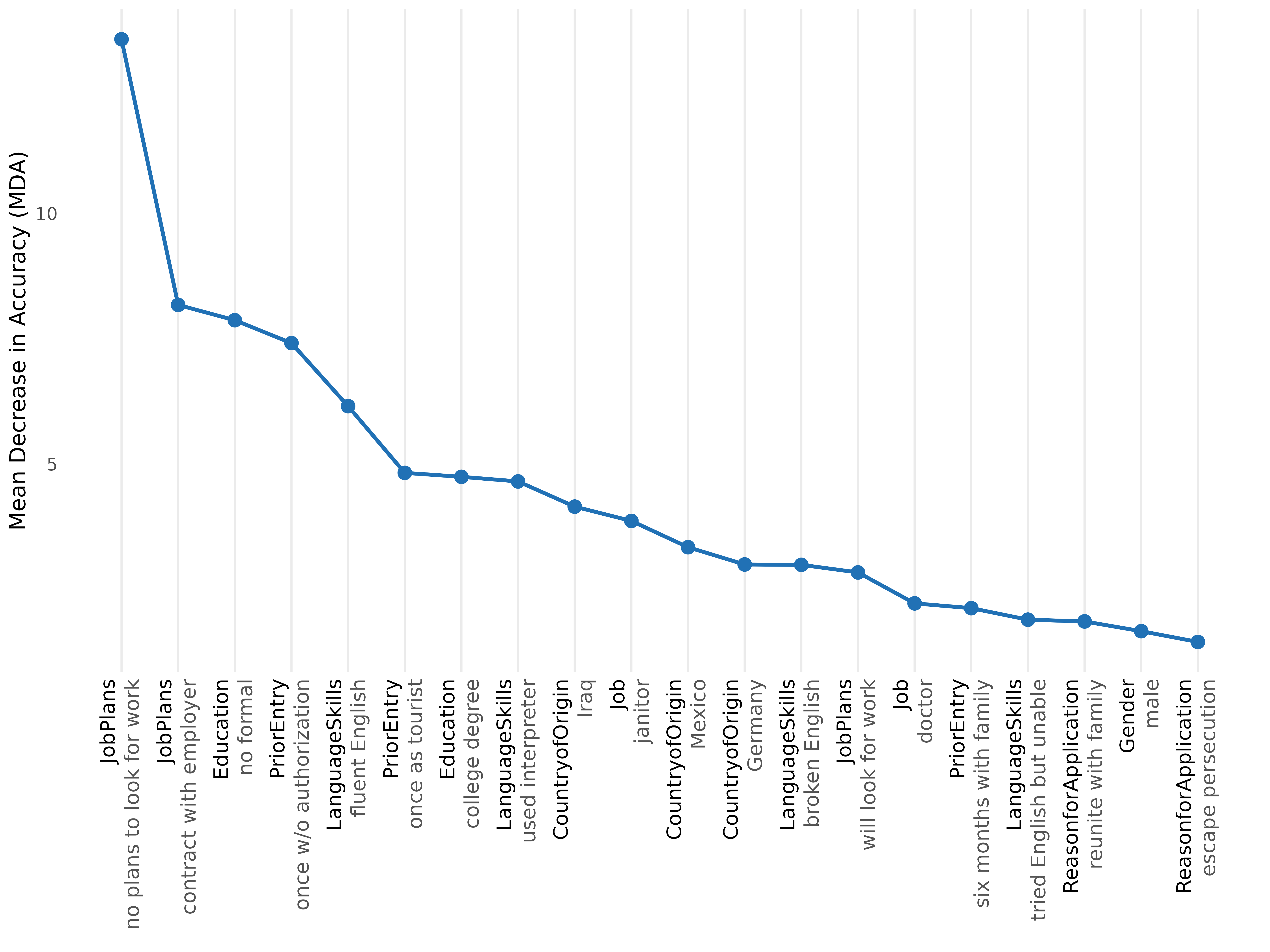
#> Top 10 levels by MDA:
#>
#> # A tibble: 10 × 7
#> rank attribute level mda root_pct class_0 class_1
#> <int> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 1 JobPlans no plans to look for wo… 13.5 15.4 12.3 7.25
#> 2 2 JobPlans contract with employer 8.18 11.2 3.70 6.98
#> 3 3 Education no formal 7.87 7.4 8.04 2.38
#> 4 4 PriorEntry once w/o authorization 7.42 10.4 6.87 3.66
#> 5 5 LanguageSkills fluent English 6.16 8.2 2.71 6.00
#> 6 6 PriorEntry once as tourist 4.83 2.4 1.61 5.25
#> 7 7 Education college degree 4.75 6.4 0.153 6.16
#> 8 8 LanguageSkills used interpreter 4.66 5.6 4.91 1.37
#> 9 9 CountryofOrigin Iraq 4.15 4.6 3.53 2.15
#> 10 10 Job janitor 3.87 3 2.09 3.36Interpret the results table
rf$results
#> # A tibble: 50 × 9
#> rank attribute level mda mdg root_pct class_0 class_1 var_name
#> <int> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
#> 1 1 JobPlans no plans… 13.5 28.2 15.4 12.3 7.25 JobPlan…
#> 2 2 JobPlans contract… 8.18 23.0 11.2 3.70 6.98 JobPlan…
#> 3 3 Education no formal 7.87 18.7 7.4 8.04 2.38 Educati…
#> 4 4 PriorEntry once w/o… 7.42 22.9 10.4 6.87 3.66 PriorEn…
#> 5 5 LanguageSkills fluent E… 6.16 22.3 8.2 2.71 6.00 Languag…
#> 6 6 PriorEntry once as … 4.83 20.3 2.4 1.61 5.25 PriorEn…
#> 7 7 Education college … 4.75 18.9 6.4 0.153 6.16 Educati…
#> 8 8 LanguageSkills used int… 4.66 20.2 5.6 4.91 1.37 Languag…
#> 9 9 CountryofOrigin Iraq 4.15 17.1 4.6 3.53 2.15 Country…
#> 10 10 Job janitor 3.87 18.0 3 2.09 3.36 Jobjani…
#> # ℹ 40 more rowsKey columns:
-
mda — Mean Decrease in Accuracy. How much the
forest’s predictive accuracy drops when this level’s values are
shuffled. Higher = more important. Levels with
mdanear zero are effectively ignored. - root_pct — % of trees in the forest where this level is the first split. The gatekeeper signal.
-
class_0 / class_1 —
class-conditional importance.
class_0large = level mostly drives rejection (deal-breaker);class_1large = level mostly drives selection (attractor).
Related
- Decision Tree for the hierarchical structure of these importances.
- Nested Marginal Means for the decision order.